
Second mission

Navázal bych na post First Mission — napsal jsem další transformační skriptík pro stejný projekt. Opět šlo o to, přečíst vstupní soubor a na základě daných podmínek změnit některé hodnoty. Soubor obsahoval informaci o sdílených telefonech:
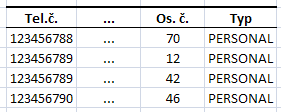
Tam, kde byla pro stejný telefon různá osobní čísla mělo dojít ke změně typu z PERSONAL na SHARED:
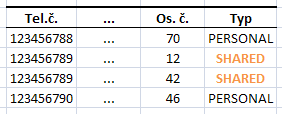
Měl jsem trochu obavy z “performance” (soubory mají 10k — 50k řádků), tak jsem to udělal na dva průchody — při prvním průchodu se do mapy vložily telefony, které měly více os. čísel a při druhém průchodu, kdy se všechny záznamy zapisovaly do upraveného souboru, se tyto záznamy měnily.
Skriptík je samozřejmě triviální, ale podstatné jsou věci, které jsem se přitom naučil — pořádně pracovat s Refs a transakcema (STM):
(def phones (ref {}))
(defn add-phone [phone pers-num]
(if (contains? @phones phone)
(if (contains? (@phones phone) pers-num)
(println "Duplicate record:" phone pers-num)
(dosync
(ref-set phones (update-in @phones [phone]
conj pers-num))))
(dosync
(ref-set phones (assoc @phones phone
#{pers-num})))))
(add-phone :123456789 :12)
(add-phone :123456789 :42)
(add-phone :123456789 :12)
(add-phone :123456790 :36)
(println @phones)
; Duplicate record: :123456789 :12
; {:123456790 #{:36}, :123456789 #{:12 :42}}
Další šikovná věc je “filrování mapy”:
(defn get-shared [m]
(select-keys m (for [[k v] m :when
(> (count v) 1)] k)))
(println
(get-shared
{:123456790 #{:36}, :123456789 #{:12 :42}})
; {:123456789 #{:12 :42}}
K tématu Refs bych se v budoucnu ještě rád vrátil — hned potom, co ze zásobníku vyndám a zpracuju sekvence.