
Odhady pracnosti softwaru
Zrovna čtu, paralelně, tři knížky — klasiky The Pragmatic Programmer, The Mythical Man-Month a The Passionate Programmer, což sice není klasika, ale výborná knížka to podle mne je. Všechny tři knihy (i když každá jiným způsobem) se zabývají tématem “sebezušlechtění programátora”, ať už na poli kariérním, tak na poli praktickém.
V PragProg je kapitola o odhadech. Protože mi předestírané řešení/postupy konvenují, resp. jsem k nim došel intuitivně víceméně také, protože jsem v uplynulých dvou měsících dělal odhady na cca pět projektů v hodnotě 5-30 mil. a protože se mě kolega nedávno zeptal, “jestli máme ve firmě nějakou metodiku na odhady” (nemáme), přišlo mi to jako vhodné téma na blogpost.
Nejprve ve zkratce, co radí PragProg:
- Porozumnění tomu, co je požadováno.
- Vytvoření modelu systému.
- Rozbití modelu do komponent.
- Ohodnocení parametrů.
- “Výpočet” odpovědí.
- Průběžná kontrola odhadů (tracking).
Každý bod by chtěl trochu rozvést, ale to si můžete přečíst v knížce. Pouze bych zde ocitoval důležitou radu:
Základní trik v odhadech, který dává vždycky dobré výsledky: zeptejte se někoho, kdo už něco takového (projekt, problém) dělal.
Můj postup je z velké části podobný. Nejdříve se snažím získat co nejvíc informací. Většinou dostanu do ruky poptávku, plus se snažím zjistit kdo ve firmě dělal něco podobného, pracoval/pracuje u daného zákazníka, má zkušenosti s danou technologií, apod.
Jako model používám hrubou kostru projektu. Aby to neimplikovalo vodopád (někdy to je, někdy ne), uvedu jen uvažované role:
- projekt manažer,
- architekt,
- vývojář,
- tester,
- dokumentátor.
Role se mohou různě překrývat, čili role != člověk. Jako vývojář mívám na starost architekturu a vývoj. Pokud musím odhadovat i zbylé role/části projektu, dávám tam nějakou konstantu vůči vývoji, např. testování = 30 % vývoje. 30 % na vývoj se může zdát málo (alespoň podle Mythical Man-Month), ale jednak počítám že vývojáři píšou unit (a integrační) testy a jednak, že tester je přítomen během celého vývoje, tj. netestuje až na konci vývoje (UAT), takže většinu chyb odchytí během jednotlivých iterací.
Pak si v Excelu rozpadnu jednotlivé role v rámci týmu na komponenty. U každé komponenty si představím, kolik lidí by ji optimálně mělo dělat a jak dlouho by jim to mělo trvat. Tohle je těžká část a myslím si, že jinak než praxí a trénováním odhadů se to dělat nedá. Pokud si to nemám k čemu vztáhnout, je to opravdu… odhad. Excel, který používám se projekt od projektu liší, ale může vypadat přibližně takto:
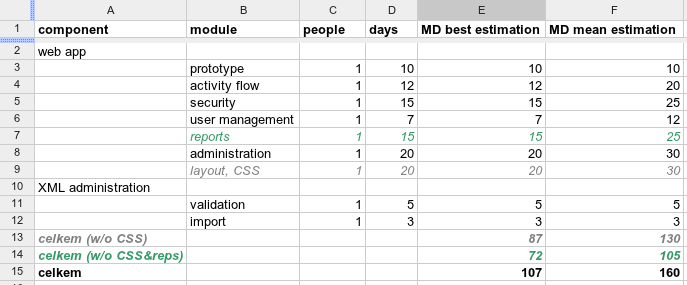
Důležitý jsou poslední dva sloupce. MD best estimation je můj odhad nejkratšího času, za který se dá daný komponent vytvořit. Tj. všechno jde “podle plánu”, nejsou žádné problémy, tasky dělají kvalifikovaní lidé, atd. MD mean estimation je odhad best estimation vynásobený nějakou konstantou (> 1). Velikost konstanty se pro jednotlivé komponenty liší a opět ji určuju na základě zkušeností. Číslo, který pak dávám k dispozici jako svůj odhad, je suma mean estimation.
Samozřejmě projekty se liší a občas je potřeba udělat nějakou “magii nad čísly”, ale víceméně se držím výše popsané kostry. Aspektů o kterých by se dalo psát je hodně (bylo by to na článek,nebo na knihu), tak třeba někdy příště, až mě zase něco trkne. Dal bych jen několik doporučení:
- Odhady se dají trénovat. Člověk by měl už jako junior odhadovat tasky které dostává — jsou malé a dá se na nich dobře “zastřílet”. Jak člověk “seniorní” dostává se k větším a větším taskům a pak i projektům a má pak na čem stavět.
- Opravdu se na tím zamyslet. Tj. zanalyzovat problém, zkusit ho dekomponovat, nakreslit si to, atd. Pomocníky jsou Excel, nějaké kreslítko (UML, mind mapy, diagramy, papír a tužka).
- Sbírat informace — knížky, kolegové, atd.
A na úplný závěr. Dávám vždycky odhady, jak si myslím, že to je, tj. nenásobím dvěma, protože mi to pak někdo ořeže. Rovněž nedávám tzv. “finger-sucking” a “window-outlooking” odhady, ale snažím se to vždy vztáhnout k něčemu ukotvenému v reálu. Spolu s trénováním pak ve výsledku dostávám odhady se slušnou mírou přesnosti.