
Map a reduce, funkcionální elegance

Na svém druhém blogu o softwarovém inženýrství jsem se pustil do kratičké série o Hadoopu — Java implementaci MapReduce. Protože tento algoritmus je inspirován dvěma funkcemi pocházejícími z funkcionálního programování — map a reduce — podíval bych se trochu blíže, jak tyto funkce vypadají v Clojure.
Map
Začněme výpisem dokumentace a odkazem na referenci:
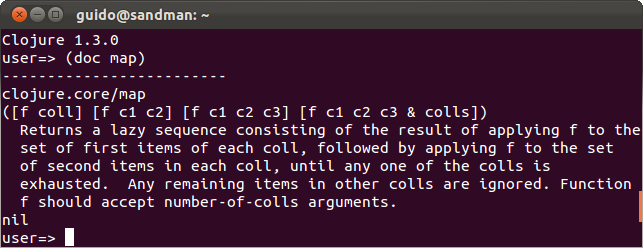
Dokumentace funkce map
Jak je vidět, funkce map přijímá v nejjednodušší podobě dva parametry — funkci a kolekci. Na každou položku kolekce pak aplikuje danou funkci.
(map inc '(1 2 3))
;=> (2 3 4)
(map #(* % %) '(1 2 3))
;=> (1 4 9)
(map #(.toUpperCase %) '("a" "b" "c"))
;=> ("A" "B" "C")
Pokud v argumentech po funkci následuje více kolekcí, je funkce postupně aplikována na všechny první položky, druhé položky atd., dokud v jedné z kolekcí nedojde počet položek.
(map str '(1 2 3 4) '("a" "b" "c"))
;=> ("1a" "2b" "3c")
; takes the first column
(map first [[:a1 :a2 :a3]
[:b1 :b2 :b3]
[:c1 :c2 :c3]])
;=> (:a1 :b1 :c1)
; removes the first column
(map rest [[:a1 :a2 :a3]
[:b1 :b2 :b3]
[:c1 :c2 :c3]])
;=> ((:a2 :a3)
; (:b2 :b3)
; (:c2 :c3))
Reduce
Jestliže u funkce map vkládáme do funkce kolekci a výsledkem je opět (nějak zpracovaná) kolekce, u funkce reduce sice také vkládáme do funkce kolekci, ale výsledkem je jedna hodnota, objekt, entita. Algoritmus je následující: funkce reduce vezme úvodní hodotu a první hodnotu z kolekce a aplikuje na ně danou funkci, pak vezme výsledek a druhou hodnotu z kolekce a aplikuje na ně danou funkci. Takto iteruje až do konce kolekce.
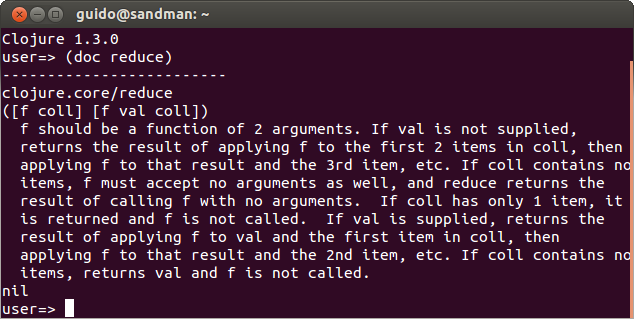
Dokumentace funkce reduce
Pokud funkce neobsahuje úvodní hodnotu, je první aplikace funkce na první dvě hodnoty kolekce. Zbytek už je stejný.
(reduce * '(3 4 5))
;=> 60
(reduce * 2 '(3 4 5))
;=> 120
(reduce + (range 1 1000001))
;=> 500000500000
(reduce max '(7 4 -3 42 -6 12))
;=> 42
(reduce conj [1 2] [3 4 5])
;=> [1 2 3 4 5]
Příklad
Pojďme si teď napsat praktický příklad, na kterém si obě funkce vyzkoušíme a to i s postupným výkladem, jak jsme se k jejich potřebě dopracovali. Dejme tomu, že chci mít funkci, která mi vrací SHA-1 hash daného řetěze. Něco jako:
(sha1 "Sometimes Clojure")
;=> "339e36ff40c581cebf3bec542c9a699a4ffbb453"
Pro výpočet hashe (digestu) použijeme Java třídu MessageDigest. Naše funkce by mohla vypadat nějak takhle:
(import java.security.MessageDigest)
(defn digest [string]
(.digest (MessageDigest/getInstance "SHA-1")
(.getBytes string)))
(digest "Sometimes Clojure")
;=> #<byte[] [B@36d6526d>
Metoda/funkce digest (ta naše i ta Javovská) vrací pole bytů (binární řetězec). Můžeme si je prohlédnou např. příkazem:
(reduce conj [] (digest "Sometimes Clojure"))
;=> [51 -98 54 -1 64 -59 -127 -50 -65 59
; -20 84 44 -102 105 -102 79 -5 -76 83]
(apply vector (digest "Sometimes Clojure"))
;=> [51 -98 54 -1 64 -59 -127 -50 -65 59
; -20 84 44 -102 105 -102 79 -5 -76 83]
Pokud bychom pole bytů převedli na řetězec, nebude to asi to, co bychom čekali:
(String. (digest "Sometimes Clojure"))
;=> "3�6�@Łο;�T,�i�O�"
Napíšeme si proto pomocnou funkci, která převede byte na hexadecimální hodnotu:
(defn hex [bt]
(if (< (bit-and 0xff bt) 0x10)
(str 0 (Integer/toHexString (bit-and 0xff bt)))
(Integer/toHexString (bit-and 0xff bt))))
Nyní již můžeme použít funkci map, abychom získali hash v podobě hexadecimálního pole:
(map hex (digest "Sometimes Clojure"))
;=> ("33" "9e" "36" "ff" "40" "c5" "81" "ce" "bf" "3b"
; "ec" "54" "2c" "9a" "69" "9a" "4f" "fb" "b4" "53")
No a samozřejmě, že cílem je, mít hash jako řetězec. K tomu nám dopomůže právě funkce reduce:
(reduce str (map hex (digest "Sometimes Clojure")))
;=> "339e36ff40c581cebf3bec542c9a699a4ffbb453"
Celý kód pak vypadá takto:
(ns blog-map-reduce.core
(:import java.security.MessageDigest))
(defn digest [string]
"Returns a SHA-1 digest of the given string."
(.digest (MessageDigest/getInstance "SHA-1")
(.getBytes string)))
(defn hex [bt]
"Returns a hexadecimal value of the given byte."
(if (< (bit-and 0xff bt) 0x10)
(str 0 (Integer/toHexString (bit-and 0xff bt)))
(Integer/toHexString (bit-and 0xff bt))))
(defn sha1 [string]
"Returns a SHA-1 hash of the given string."
(reduce str (map hex (digest string))))
S funkcemi si pak můžeme hrát ještě dál. Můžeme např. mít pole řetězců a budeme chtít vrátit pole hashů:
(map sha1 '("Sometimes Clojure" "Guido"))
;=> ("339e36ff40c581cebf3bec542c9a699a4ffbb453"
; "28aeafc90fae0f3318d4bdf5b1a59e5dc506b50a")
A nebo můžeme jít ještě dál a chtít jako výsledek mapu, kde hash bude klíčem k původnímu řetezci. Hash-klíče navíc převedeme, kvůli performance, na Clojure keywords:
(defn sha1-map [strings]
"Returns a map of SHA-1 hashes as a keyword keys
and given string as a value."
(zipmap (map keyword (map sha1 strings)) strings))
(sha1-map '("Sometimes Clojure" "Guido"))
;=> {:28aeafc90fae0f3318d4bdf5b1a59e5dc506b50a
; "Guido",
; :339e36ff40c581cebf3bec542c9a699a4ffbb453
; "Sometimes Clojure"}
Závěr
V nadpisu jsem zmiňoval (funkcionální) eleganci. Pro vyznavače Clojure a Lispu je to samozřejmě nošením sov do Athén. Nicméně i člověk nezasažený Lispovskou syntaxí a funkcionálním programováním by mohl uznat, že uvedené ukázky jsou elegantní a pokud si za Lisp/Clojure dosadíme pseudo-kód, tak i čitelné a pochopitelné.
Jen pro představu, jak by vypadal výše uvedený kód v jiném jazyce, jsem přepsal funkci sha1-map do Groovy. Při srovnání bych řekl, že kód v Groovy je “ukecanější” a méně flexibilnější než ten v Clojure. To samozřejmě není nic proti tomu, pokud bychom to srovnávali s Javou — Groovy má alespoň metodu each, která přijímá closure.
import java.security.MessageDigest
def digest(string) {
def md = MessageDigest.getInstance("SHA-1")
md.digest(string.getBytes())
}
def hex(bt) {
if ((0xff & bt) < 0x10) {
"0" + Integer.toHexString(0xff & bt)
} else {
Integer.toHexString(0xff & bt)
}
}
def sha1(string) {
def result = new StringBuilder()
digest(string).each {
result.append(hex(it))
}
result
}
def sha1Map(strings) {
def result = new HashMap()
strings.each {
result.put(sha1(it), it)
}
result
}
sha1Map(["Sometimes Groovy", "Guido"])
// [28aeafc90fae0f3318d4bdf5b1a59e5dc506b50a :
// Guido,
// ac0416ec9a83cd93a5f5a2aa5e6a452cd33840db :
// Sometimes Groovy]