
Fluentd, lehký úvod (část 2)

Dnes budeme pokračovat dalším dílem minisérie o Fluentd. Minule jsme si řekli něco o historii logování a zasadili si Fluentd do kontextu. A trochu jsme si načrtli architekturu a design.
Dnes se podíváme, jak si nakonfigurovat jednoduchou logovací infrastrukturu. Ale ještě před tím, se krátce vrátím k minulému článku.
Lesk a bída bulvárních titulků
Když jsem předešlý článek nazval Fluentd, budoucnost logování, měl jsem u toho postranní úmysly. Respektive, nemyslel jsem to úplně vážně. Jako na krev. (Jinak, pravda to samozřejmě je. 😈) Ale zafungovalo to — na Twitteru se lehce rozproudila diskuze a u dvou názorů bych se rád pozastavil.
Je JSON budoucnost logování? Ne
Díky, jako programovací dinosaurus tyhle články potřebuju. Co mě ale fyzicky zabolelo je, že žádné pokračování věty "Jestliže máme data určená přednostně pro stroje, nabízí se několik osvědčených řešení. Fluentd si vybralo dnes všudypřítomný JSON..." nemůže napravit její vyznění.
— František Řezáč (@calaverainfo) October 2, 2020
Ten původní odstavec (ve kterém jsem 4x napsal slovo JSON 🙄) jsem neformuloval úplně šťastně — nechtěně jsem zdůraznil přenosový formát, který je vlastně úplně nepodstatný.
To, co se mi na Fluentd líbí (a proč si myslím, že je to dobré moderní řešení), souvisí s designem, architekturou, otevřeností založenou na pluginech a dobrým pokrytím vstupních a výstupních kanálů (zajištěnou core pluginy).
O JSONu si každý můžeme myslet co chceme, ale buď jak buď, je to lingua franca současného cloudu. Ať už na úrovni infrastruktury (moje doména), nebo aplikací. 🤷♂️
Je telemetry budoucností logování? Ne
Krása Telemetry je, že klasické logování nahrazuje a posouvá ho o úroveň dál.
— Zdeněk Merta (@zmerta) October 3, 2020
Do Spanu se dají přidávat Events. Event může být třeba log.
Honeycomb to pekně vysvětlujehttps://t.co/KOc6DP8eUU
V OpenTelemetry je to podobné.
Hodně zajímavá a (pro mne) přínosná byla diskuze o telemetry a jestli nahrazuje (a je lepší než) logování. Myslím si, že jsou to nesouvisející témata. Alespoň z hlediska Fluentd — tomu je totiž jedno, jaký obsah přenáší (hlavně, že je strukturovaný). Takže klidně může přenášet metriky. Nebo může přenášet logy ve formátu events. Je to jen na vás, co budou vaše aplikace produkovat. 🤷♂️
Mimochodem, odkazované OpenTelemetry, je také součástí CNCF, stejně jako Fluentd, nebo třeba Prometheus (etalon metrik). Co může vést k neporozumění na základě výše zmíněného článku, API a výstupní formát může být identický jak pro events, tak pro metriky, tak pro logy. Ale jejich smysl a použití je diametrálně jiné. Už proto, že jde o rozdílné typy dat — log record (event) je jednorozměrná textová zpráva (může mít atributy), metrika je/může být vícerozměrná číselná hodnota, reprezentovaná jako číselná řada.
Každopádně, (Fluentd) metrikám se budu alespoň letmo věnovat v příštím článku.
Jednoduchá Fluentd pipeline
Dost bylo filozofování, pojďme se podívat na reálný kód. S něčím takovým budete pravděpodobně začínat, možná to bude vaše PoC, či prostě pouhé vyzkoušení Fluentd. Vezměme si jednoduchý use case:
- Logovací soubory v JSON formátu budou uloženy v definované adresářové struktuře.
- Uděláme jednoduchou sanitizaci, že logy jsou ve formátu UTF-8.
- Logy pošleme do Elasticsearch (čistě jen z důvodu, abychom si je jednoduše a agregovaně zobrazili).
Načtení logů
Naším úkolem bude načíst logy z následující struktury:
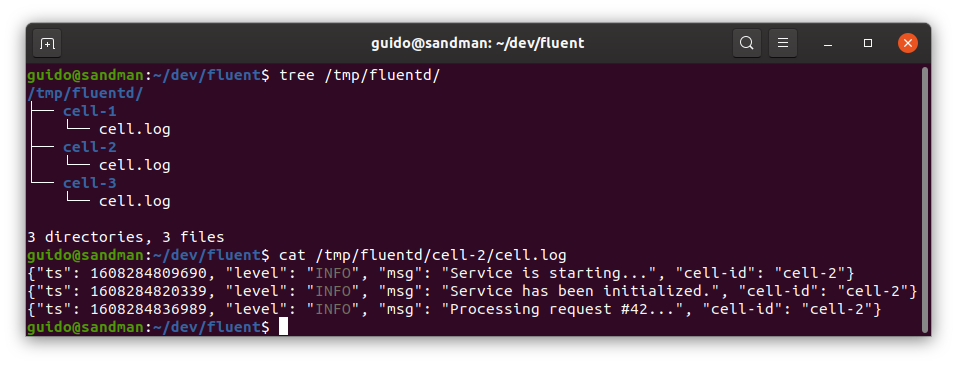
Adresářová struktura a výpis jednoho logu
Čili:
- Každý log má svůj adresář,
- log je strukturovaný (atributy
msg,level,cell-id), - časový identifikátor (atribut
ts) je Unix timestamp v milisekundách.
Pro tento účel je ideální tail plugin, který se chová obdobně jako klasický unixový tail — čte z konce souboru, resp. nově přidané řádky.
Atributy konfigurace jsou docela samopopisné, takže nepůjdu do detailu, ale u dvou z nich bych se zastavil.
Pokud aplikace hned po vzniku logovacího souboru do něj ihned velmi rychle zapisuje (v mém případě to byly milisekundy a desítky záznamů), může se stát, že tyto úvodní zprávy budou ignorovány. 😢 Důvod je ten, že Fluentd nejprve daný soubor zaregistruje pro sledování (viz následující výpis) a až teprve potom začne sledovat přibývající záznamy.
2020-12-18 10:54:06 [info]: following tail of /home/guido/dev/fluent/cell-1/cell.log
Řešením je nastavit atribut read_from_head na true. Nový soubor je tak čten
vždy od začátku.
Samozřejmě, není efektivní číst soubor a nevědět, kde jsme se čtením skončili
minule. Proto je dobré nastavit position file (atribute pos_file), který
drží ukazatel na poslední čtenou pozici v každém sledovaném souboru.
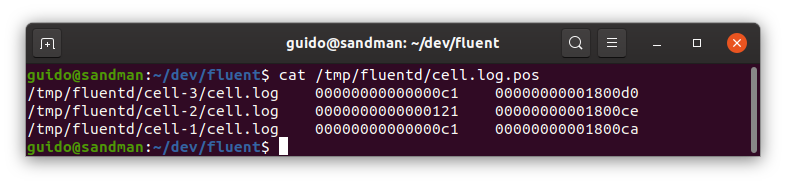
Pozice čtení pro jednotlivé logy
Filtrování logů
OK, logy máme načtený (někde uvnitř Fluentd) a než je převážeme mašlí a doručíme, chceme je trochu porychtovat. Přichází ke slovu filter pluginy. Ty mají na starosti filtrovat, či/a transformovat jednotlivé záznamy, než se posunou do výstupních pluginů.
Řekněme, že máme následující use case: představme si (čistě hypoteticky 😈), že se nemůžeme spolehnout na to, že nám vývojáři sypou do logů záznamy v očekávaném kódování. Takže než je posuneme dál, chceme záznamy pročistit, sanitizovat.
Poslouží nám record_transformer plugin.
Jak název napovídá, transformuje jednotlivé záznamy. Za zmínku stojí jeho atribut
enable_ruby, který umožní používat Ruby výrazy (není
to tak zlé, jak to zní 🤭).
Konkrétně zde projdeme všechny záznamy a pokud tento obsahuje nějaké illegální
UTF-8 znaky, 😱 nahradí je řetězcem __NON_ASCII_CHAR__.
Publikování logů
Už máme skoro hotovo — zbývá záznamy někam publikovat, stačí si vybrat vhodný output plugin. V případě, že chceme záznamy publikovat do více cílových platforem, použije se copy plugin. V našem případě to ale uděláme jednoduše, starý dobrý Elasticsearch:
Nastavování Elasticsearch a případně Kibany zde přeskočíme (to už přece dávno umíte 😉) a podíváme se rovnou na výsledek:
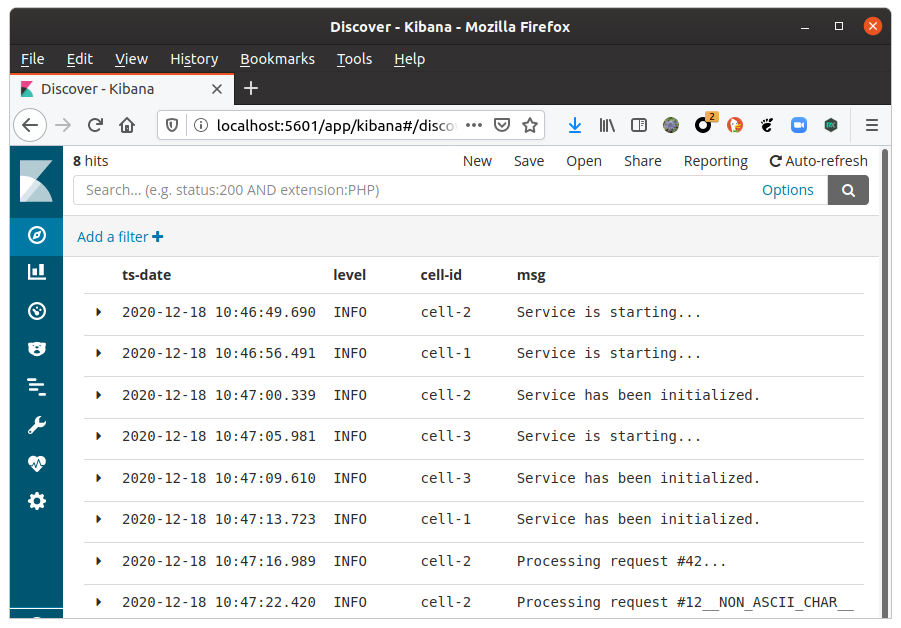
Logy přenesené do Elasticsearch, zobrazené v Kibaně
Celá konfigurace
Pokračování příště
Ne, nebojte se — nebude to nekonečný seriál. Ale jak se situace vyvíjí, budu muset přidat ještě jeden díl. Tentokrát už určitě závěrečný. 😈
A na co, že se podíváme? Na reálný use case, který se časem vyvinul v docela komplexní řešení.